Summary
이번 글에서는 Monster agent 와 ELK stack 을 연동을 통해 시스템 이벤트를 실시간으로 수집하고, 수집한 데이터를 통해 대시보드를 구성하는 방법을 상세히 다룹니다. 이를 통해 시스템의 이상 행위를 모니터링 하고 탐지할 수 있으며, 나아가 보안 위협 탐지에 적극적으로 활용할 수 있음을 보여줍니다.
Monster agent가 수집하는 이벤트들의 종류와 내용Monster agent와 Elastic search, Logstash, Kibana (이하ELK stack) 연동하는 방법Logstash를 활용하여 이벤트 필터링, 올바른 색인화 작업과 메타데이터를 최적화하는 방법Kibana를 활용하여 대시보드를 구성하는 방법
Expectations
이 블로그 게시물을 끝까지 읽고 난 후 다음 그림과 같은 대시보드 화면을 구성할 수 있게 될 것입니다. ELK 스택을 아직 구성하지 않은 경우 ELK 스택 설치를 먼저 보시는 것을 추천합니다. Kibana는 대시 보드 기능 이외에도 timelion을 활용하여 다양한 시계열 분석을 시도해 볼 수 있습니다. timelion은 엘라스틱서치 공식 블로그에 소개된 튜토리얼에 상세 설명되어 있습니다.
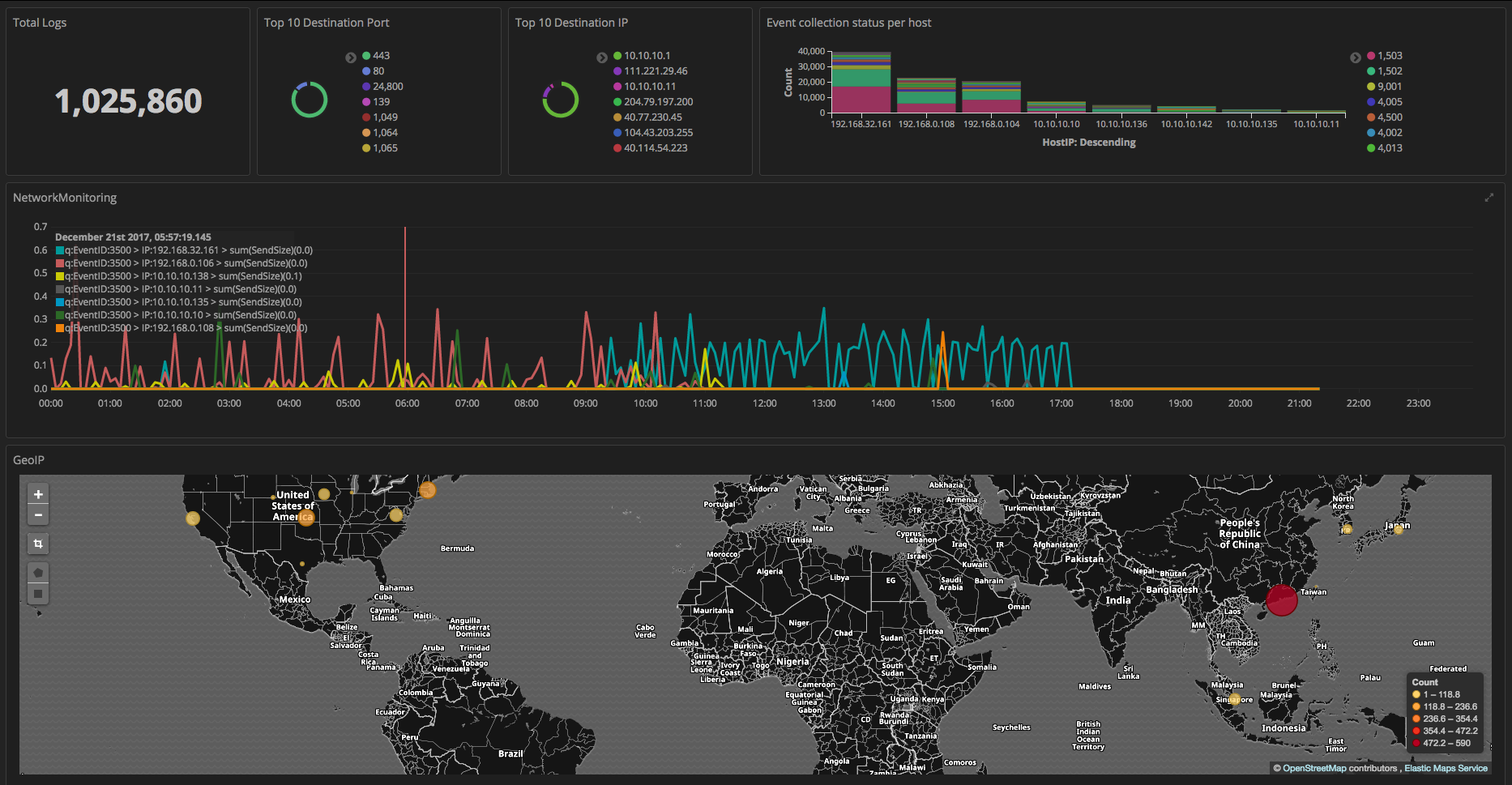
Know your Monster Agent Events
Monster agent는 프로세스 생성 후 발생하는 모든 행위를 추적하여 수집합니다. 수집된 이벤트들은 블록 단위로 구성하여 TSV 파일에 저장하거나 외부 시스템으로 전송합니다. 이벤트 블록은 발생한 행위에 대한 요약 정보와 상세 정보로 구성되어 있습니다. 요약 정보는 파일 쓰기 횟수, 파일을 쓴 크기, 파일명 변경이 발생한 경우 변경 후의 이름과 같은 정보를 수집합니다.
Statistics of Events
| EventID | Type | Description |
|---|---|---|
| 1500 | statistics | 프로세스 생성시 수집되는 이벤트입니다. |
| 1501 | statistics | 프로세스 종료시 수집되는 이벤트입니다. |
| 1502 | statistics | 프로세스에서 이미지가 로드될 때 수집되는 이벤트입니다. |
| 1503 | statistics | 프로세스에서 이미지가 언로드될 때 수집되는 이벤트입니다. |
| 2500 | statistics | 프로세스에 의해 발생한 파일 이벤트의 요약 정보입니다. |
| 3500 | statistics | 프로세스에 의해 발생한 네트워크 이벤트(connect)의 요약 정보입니다. |
| 3501 | statistics | 프로세스에 의해 발생한 네트워크 이벤트(accept)의 요약 정보입니다. |
| 4500 | statistics | 프로세스에 의해 발생한 레지스트리 이벤트의 요약 정보입니다. |
상세 정보는 요약 정보를 통해 프로세스 생성 후 종료까지 발생한 모든 행위의 흐름을 파악 후 세부적인 행위를 추적할 때 유용하게 사용할 수 있습니다.
Detailed behavior of the event vs Details of events
| EventID | Type | Description |
|---|---|---|
| 2012 | Detailed information | 파일 이벤트가 시작될 때 수집되는 이벤트입니다. |
| 2014 | Detailed information | 파일 이벤트가 종료될 때 수집되는 이벤트입니다. |
| 2027 | Detailed information | 파일명/파일경로가 변경 될 때 수집되는 이벤트입니다. |
| 2030 | Detailed information | 새로운 파일이 생성될 때 수집되는 이벤트입니다. |
| 4001 | Detailed information | 레지스트리의 새로운 키값이 생성 될 때 수집되는 이벤트입니다. |
| 4002 | Detailed information | 레지스트리의 기존의 키를 열때 수집되는 이벤트입니다. |
| 4003 | Detailed information | 레지스트리의 기존의 키를 삭제할 때 수집되는 이벤트입니다. |
| 4005 | Detailed information | 레지스트리의 새로운 값이 생성 될 때 수집되는 이벤트입니다. |
| 4006 | Detailed information | 레지스트리의 기존 값이 삭제 될 때 수집되는 이벤트입니다. |
| 4013 | Detailed information | 레지스트리 이벤트가 종료 될 때 수집되는 이벤트입니다. |
Side Note: 상세/요약 정보의 전송 데이터 포맷은 전송 데이터 포맷 에서 확인할 수 있으며, 위에서 언급한 이벤트들을 사용하여
Kibana의 그래프, 표, 원형 차트 등을 만들 수 있습니다.
ELK Integration
Monster Agent Configuration
Monster agent는 수집되는 이벤트를 전송하기 위해서 추가적인 프로그램 설치 없이 설정 변경만으로 전송할 수 있습니다. 설정 파일 내용 중 kafka 또는 syslog 중 하나를 선택하여 전송할 수 있습니다 (Kafka 를 활용한 시스템 연동방법은 별도의 포스트에서 다룹니다). 이번 글에서는 수집된 이벤트들을 syslog 프로토콜을 사용하여 Logstash에 전송합니다.
syslog 를 활성화하기 위해서는 아래 json 설정과 같이
enabled:1server: Logstash 서버의IP주소port:1514(만약1514이외에 포트를 사용 할 경우Logstash설정에서input설정 파일의 포트도 함께 수정)
{
...
"export": {
...
"syslog": {
"enabled": 1,
"server": "logstash_ip",
"port": 1514
}
}
}
Side Note: syslog로 전송을 하는 경우 메시지를 초당 2000개 이상 처리가 가능해야 합니다. 2000개 이상을 처리하기 위해서는 커널 파라미터를 조정해야 합니다. sysctl 명령어(세부 명령어:
sudo sysctl -w net.core.rmem_max=2097152)를 사용하여 조정 할 수 있습니다.
Logstash Configuration
Logstash 는 총 3단계의 파이프라인 구조로 되어 있으며 세부적인 내용은 다음 그림과 같습니다. 데이터 생성(input), 생성된 데이터 가공(filter), 마지막으로 파일, 데이터베이스, 엘라스틱서치로 전송과 같은 작업은 output 과정에서 이루어집니다.
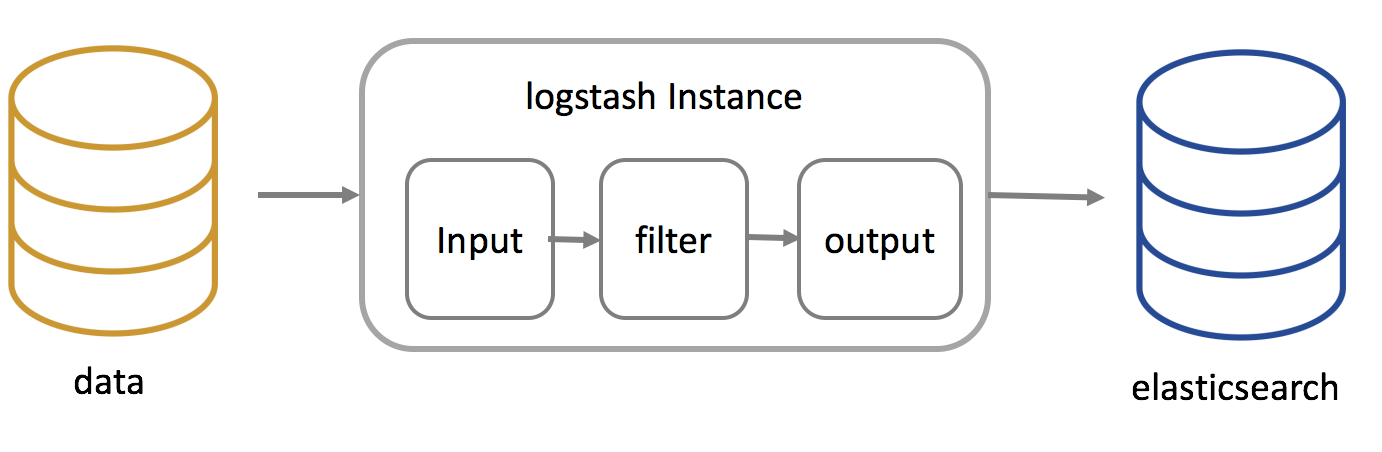
Logstash 설정 파일의 기본 템플릿은 다음과 같습니다. 파이프라인 순서(input->filter->output)로 설정 파일을 구성해야 하며 기본 경로는 /etc/logstash/conf.d/*.conf 입니다. 설정 파일명은 항상 .conf로 끝나야 합니다. 설정 파일은 단일 파일에 구성할 수 도 있으며 단계별(input, filter, outuput)로 나눈 후 설정 파일을 만들 수 있습니다.
input {
...
}
filter {
...
}
output {
...
}
Logstash input
Logstash 설치 후 사용할 수 있는 입력 플러그인은 다음과 같습니다. 플러그인 매뉴얼을 참고하여 각 플러그인에 대한 상세 설명과 세부 설정을 확인할 수 있습니다.
> sudo /usr/share/logstash/bin/logstash-plugin list
...
logstash-input-kafka
logstash-input-syslog
logstash-input-tcp
logstash-input-udp
...
/etc/lostash/conf.*.conf 폴더에 02-input-syslog.conf 파일을 다음 내용과 같이 만듭니다.
Logstash filter
Logstash 설치 후 사용할 수 있는 필터 플러그인은 다음과 같습니다. 플러그인 매뉴얼을 참고하여 플러그인에 대한 세부 설정을 확인할 수 있습니다. 필터 플러그인은 Logstash에서 핵심적인 모듈입니다. 이벤트를 수집 후 일정한 가공이 필요한 경우 플러그인(csv, json, mutate, ruby 등)을 사용하여 가공할 수 있습니다. 예를 들어, 웹서버 access.log를 수집 후 IP 만 추출 하려고 한다면 정규식을 활용하여 추출 할 수 있으며, drop 플러그인을 사용하여 로그 내용 중 응답 코드가 200인 경우는 수집하지 않을 수 있습니다. 이외에도 루비 플러그인을 이용해서 입력된 데이터를 루비 코드로 활용하여 가공할 수 있습니다. 수집된 이벤트 중 TIMESTAMP 필드의 데이터들은 루비 플러그인을 사용하여 문자열로 변경하는 것을 볼 수 있습니다.
> sudo /usr/share/logstash/bin/logstash-plugin list
...
logstash-filter-csv
logstash-filter-elasticsearch
logstash-filter-jdbc_streaming
...
Monster agent에 의해 수집된 데이터들은 TSV 포맷 이기 때문에 CSV 플러그인을 사용하여 필터링하며 기본 예제는 다음과 같습니다. 칼럼 명을 설정하지 않을 경우 Column1, Column2, Column3, Column4, Column5, ...로 정해집니다. 데이터 포맷과 일치하는 칼럼명을 미리 정한 후 autogenerate_column_names(default:true) 값을 false로 변경 후 사용하는 것이 좋습니다. separator의 기본값은 ,이기 때문에 TSV인 경우 " "로 변경하여 사용해야 합니다.
filter {
csv {
columns => ["EventID"]
separator => " "
autogenerate_column_names => false
}
}
EevnetAPI 를 사용하여 수집된 데이터를 읽은 후 가공을 하여 새로운 필드로 만들 수 있습니다. 상세 설명은 EventAPI 매뉴얼에서 확인할 수 있습니다. EventAPI 중 event.get('field_name'), event.set('field_name')를 사용하였으며, get은 데이터를 읽어오는 작업을 수행하며, set은 가공된 데이터를 필드에 저장하는 작업을 수행합니다. 윈도우 FILETIME을 문자열로 변경하는 루비 코드입니다. 엘라스틱서치는 millisecond까지만 지원하기 때문에 시간 문자열의 포맷을 '%Y-%m-%d %H:%M:%S.%3L'로 사용해야 합니다.
ruby {
code => "
puts rubyTime = Time.at(((event.get('CollectTimestamp(UTC)').to_i)/10000000) - 11644473600)
event.set('ImageCreateTime(KST)', rubyTime.strftime('%Y-%m-%d %H:%M:%S.%3L'))
"
}
geoip 플러그인을 사용하여 Maxmind GeoLite2 데이터베이스의 데이터를 기반으로 IP 주소의 지역 정보를 얻을 수 있습니다. 세부 설정은 geoip 플러그인 매뉴얼에서 확인할 수 있으며 설정은 다음과 같이 할 수 있습니다.
geoip {
source => "[DestinationIp]"
target => "[DestinationGeoip]"
}
앞서 설명한 플러그인들을 사용하여 최종적으로 작성된 설정 파일의 내용은 다운로드 한 후 /etc/lostash/conf.d 폴더에 복사 후 사용할 수 있습니다, 내용은 다음과 같습니다. if/else if/else를 사용하여 각 이벤트 아이디별 수집된 이벤트를 가공하였으며 주요 시간 값들은 문자열로 변환하도록 설정되어있습니다.
Logstash output
Logstash 설치 후 사용할 수 있는 필터 플러그인은 다음과 같습니다. 플러그인 매뉴얼을 참고 하여 플러그인에 대한 세부 설정을 확인 할 수 있습니다. 가공이 완료된 이벤트들은 플러그인(elasticsearch, csv, s3, pipe 등)을 사용하여 다양한 시스템과 연동 할 수 있습니다.
...
logstash-output-csv
logstash-output-elasticsearch
...
엘라스틱서치로 가공된 데이터를 전송하는 설정은 다음과 같으며 /etc/logstash/conf.d에 90-output-elasticsearch.conf 파일을 다음 내용과 같이 만듭니다. 만약, 동일 시스템에 엘라스틱서치를 설치하지 않은 경우 localhost 대신 ip를 입력해줘야 하며 엘라스틱서치 인덱스는 날짜별 생성합니다. 그 외의 세부 설정에 관한 설명은 플러그인 매뉴얼을 참고 하시면 됩니다.
Elasticsearch Configuration
이벤트를 수집한 후 분석을 할 때 상세한 매핑 정보 없이 할 경우 모든 데이터가 문자열로 인식이 되어 네트워크 총 수신량 / IP 주소를 기반으로한 위치 정보 확인 등의 작업은 할 수 없습니다. 그렇기 때문에 이벤트 분석 후 칼럼에 맞는 데이터 타입을 항상 설정 한 후 Kibana 에서 분석을 진행해야합니다. 또한, 인덱스가 생성 할 때마다 매핑 작업을 수행하는 것보다 템플릿을 만든 후 인덱스가 생성될 때 마다 자동으로 매핑 설정이 되도록 하는 것이 좋습니다.
| 관계형 데이터베이스 | 엘라스틱서치 |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| Index | Everything is indexed |
| SQL | Query DSL |
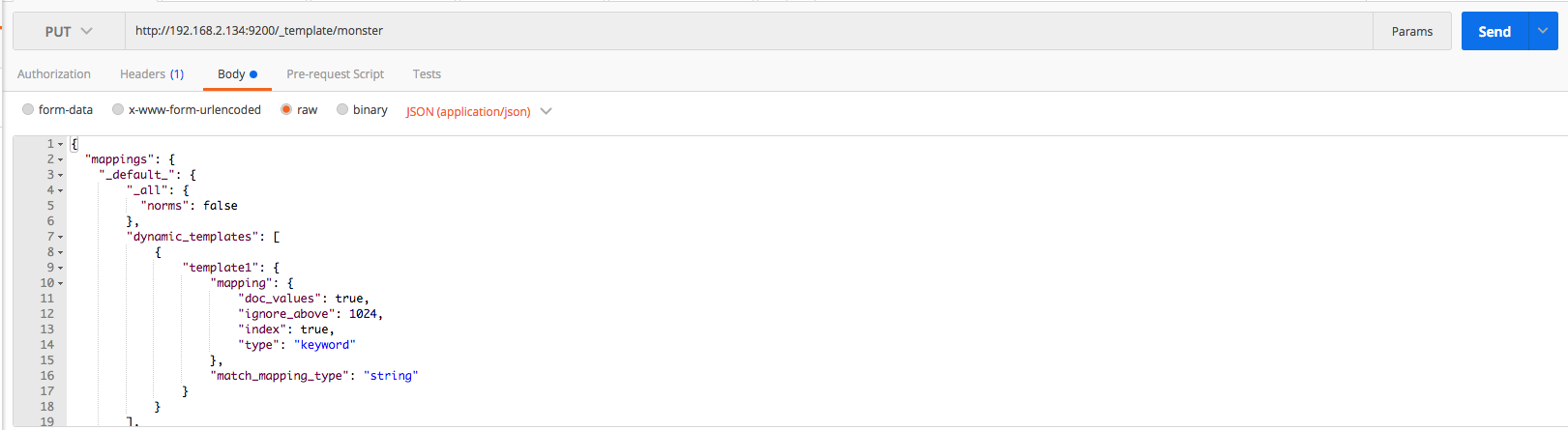
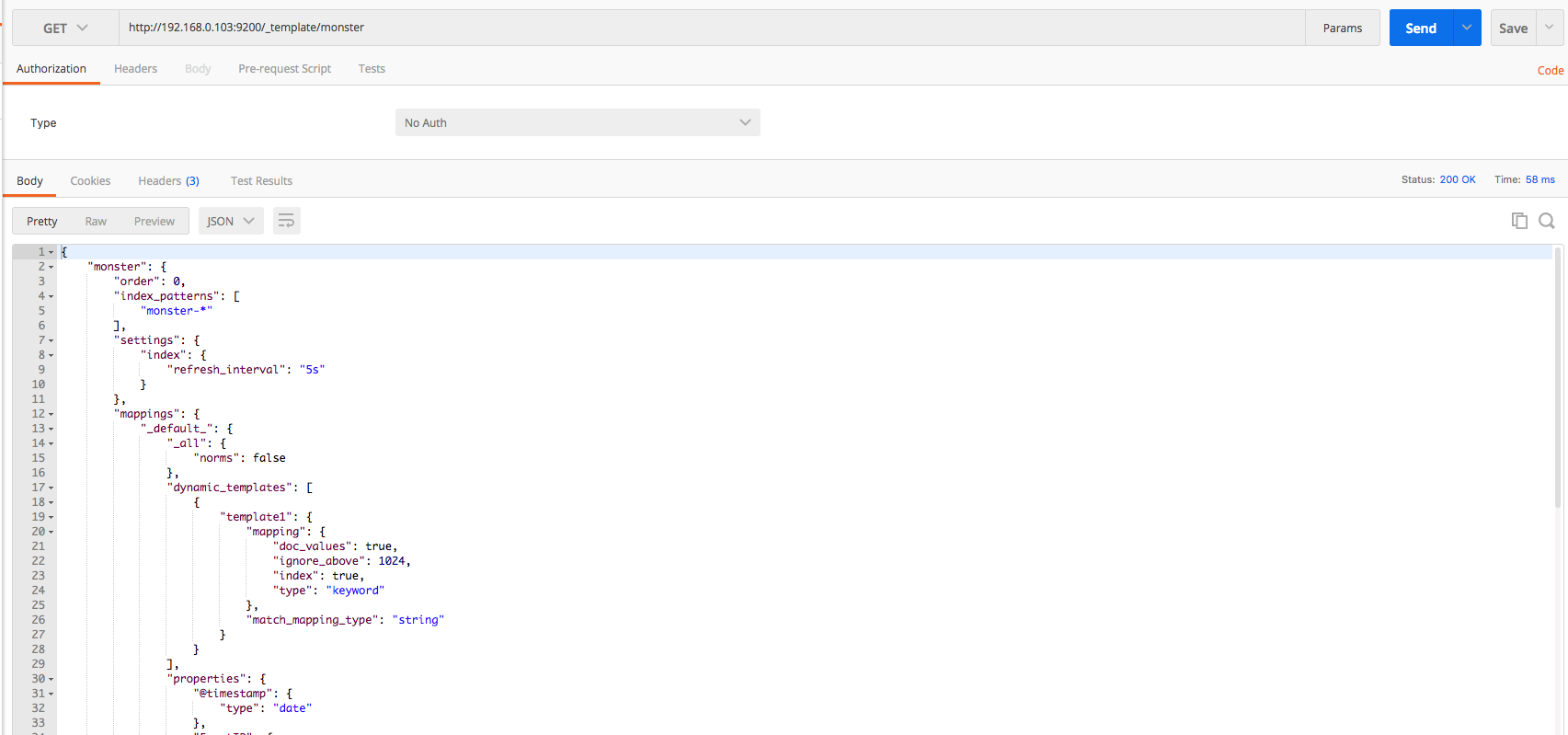
세부적인 설정 내용은 공식사이트에서 확인 할 수 있으며 몬스터 에이전트의 엘라스틱서치 매핑 템플릿은 다음과 같습니다.
매핑 템플릿 생성/삭제/확인을 할 때는 postman 혹은 키바나를 사용 할 수 있습니다. 템플릿 생성인 경우에는 put, 확인은 get, 삭제는 delete 메소드를 사용합니다. 매핑 템플릿은 저장소에서 다운 받을 수 있습니다. 전체 적인 과정은 다음 그림들을 참고하여 진행 하면 됩니다.

Kibana Configuration
Logstash에서 가공된 이벤트들이 엘라스틱서치에 입력이 된 후 인덱싱 작업이 정상적으로 되었다면 Kibana에서 인덱스를 새롭게 하나 생성 해야 합니다. 그 과정이 다음과 같습니다. 인덱스 생성은 2개의 스텝으로 구성이 되어 있으며 첫 번째로 인덱스 명을 입력하고 다음으로 타임 필드 값을 정해 주면 정상적으로 생성이 됩니다.
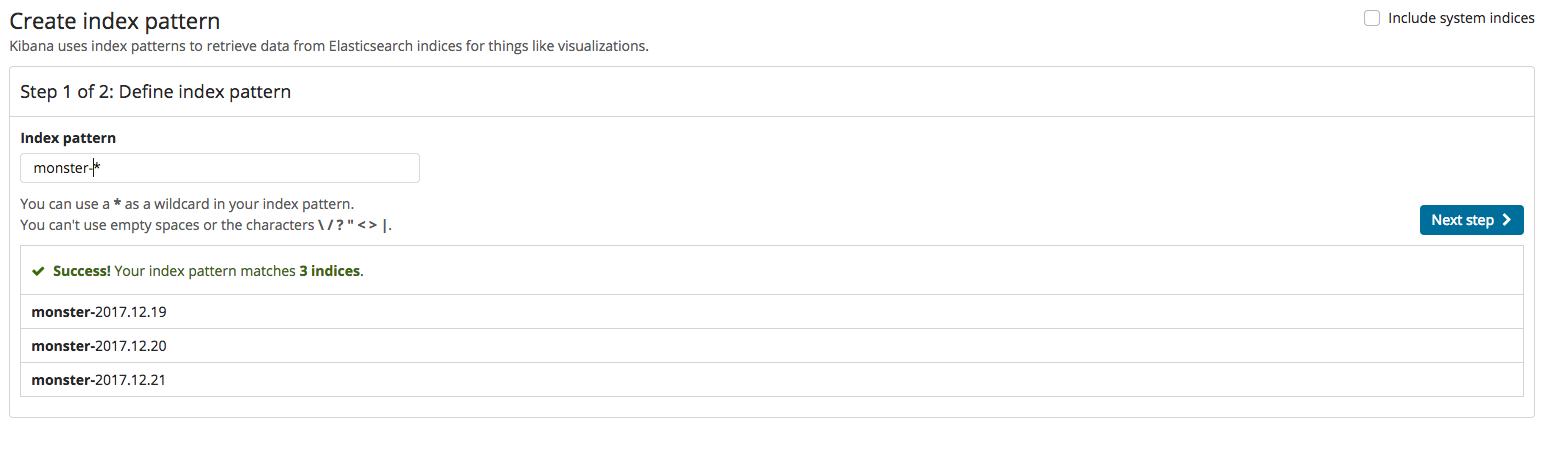
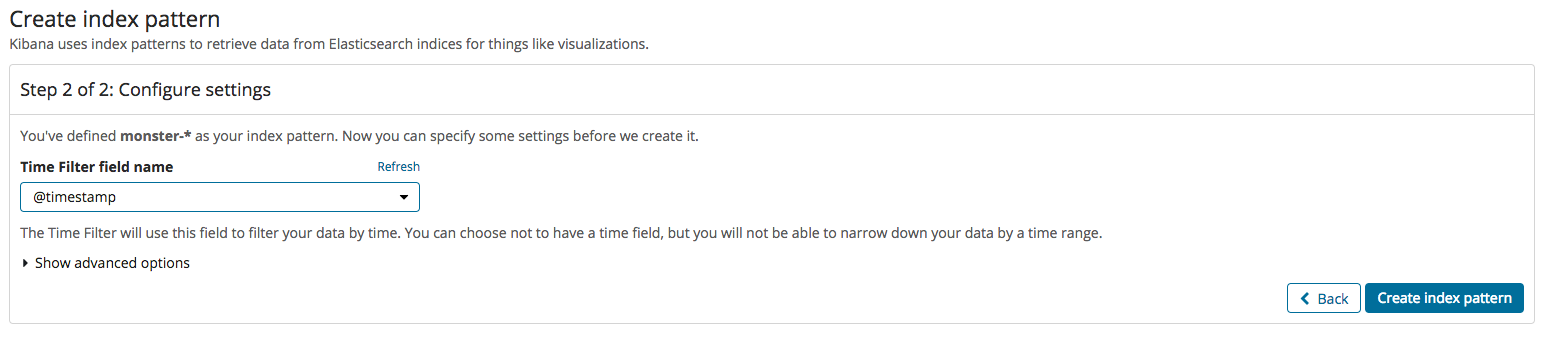
인덱스가 생성됐다면 Discover 메뉴를 클릭하면 아래와 같이 현재 수집된 이벤트들을 확인할 수 있습니다. Kibana를 이용한 대시보드를 구성하기 전 메뉴를 간략하게 설명해 드리겠습니다. Kibana의 주요 기능은 Dashboard, Discover, Visualize, Timelion 이 있습니다. Visualize에서 구성한 개별적인 시각화 요소들을 Dashboard로 구성을 할 수 있으며 수집된 이벤트들을 필터, 검색을 통해 필요한 데이터를 찾는 메뉴는 Discover 입니다. Timelion은 시계열 분석에 활용할 수 있습니다.
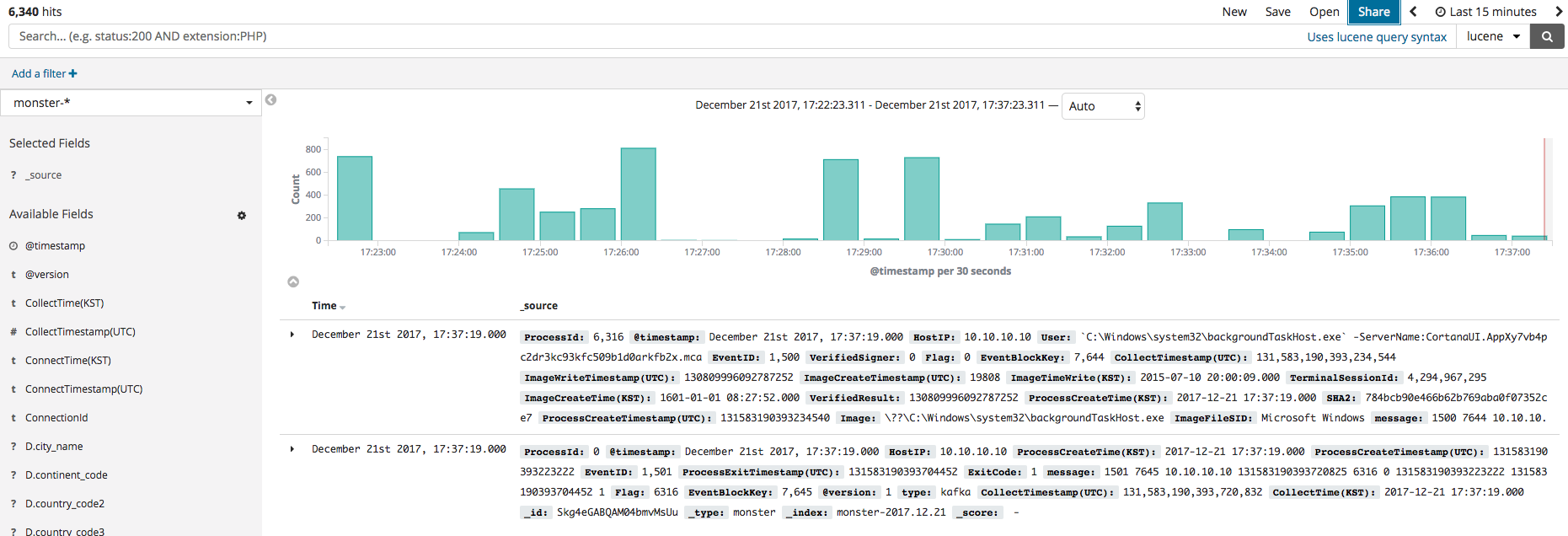
Dashboard
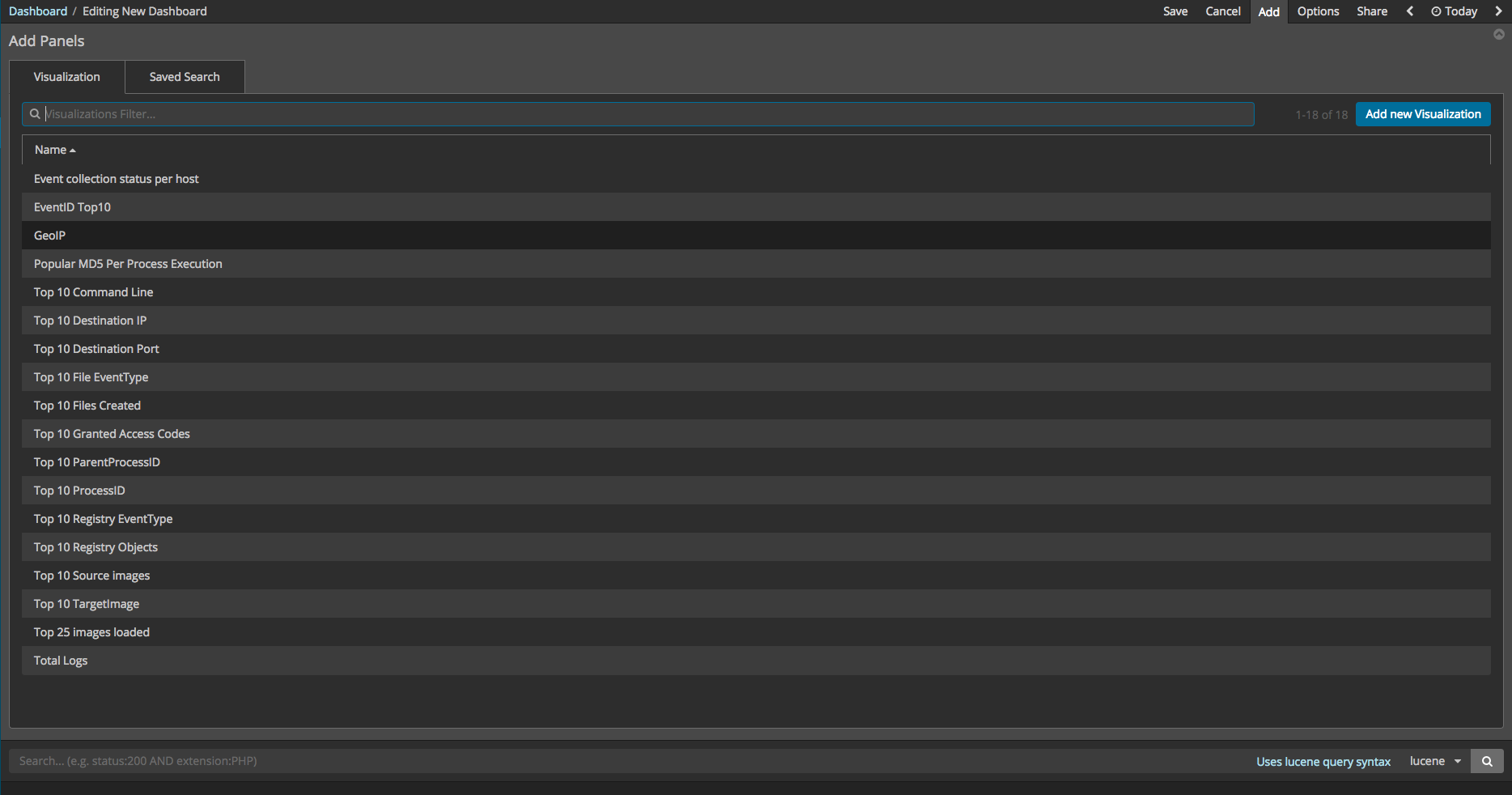
대시 보드를 구성하기 위해서는 먼저 개별적인 시각화 요소들을 만들어야 합니다. 현재 Kibana에서 지원하는 시각화 요소는 막대차트, 데이터 테이블, 지도, 시계열 분석 등이 있습니다. 개별적인 시각화 요소들을 아래 그림과 같이 만든 후 대시보드를 자신이 원하는 모양대로 설정할 수 있습니다. 또한, 시각화 요소를 만들기 위해서는 어그리게이션(Aggregation), 버킷(Bucket), 메트릭(Metric)을 알고 있어야 합니다. 어그리게이션은 개별 다큐먼트의 검색이 아닌 전체 데이터 세트의 분석 및 요약을 제공하는 것을 말하며 버킷은 특정 기준을 만족하는 다큐먼트의 집합입니다. 메트릭은 버킷에 포함된 다큐먼트에서 계산된 통계치이며 모든 어그리게이션은 하나 이상의 버킷들과 1개 이상의 메트릭과의 조합입니다.
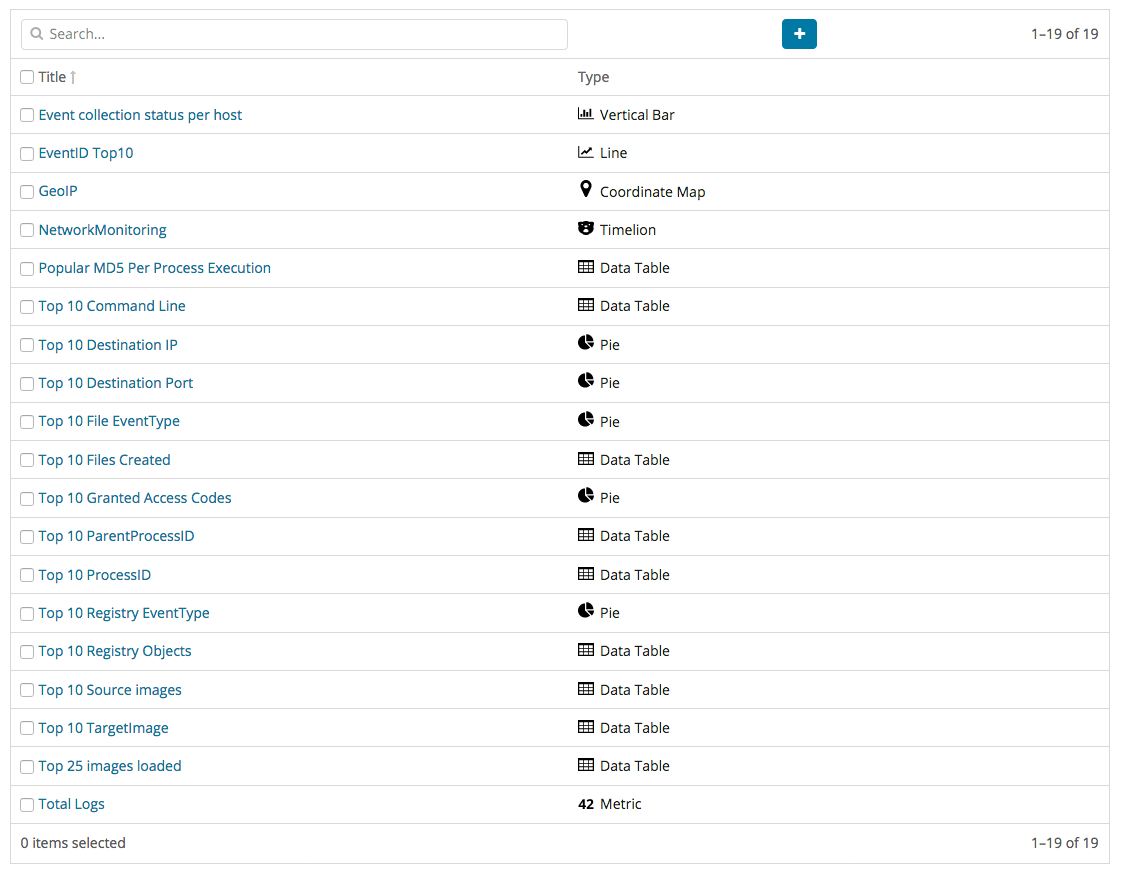
Data Table
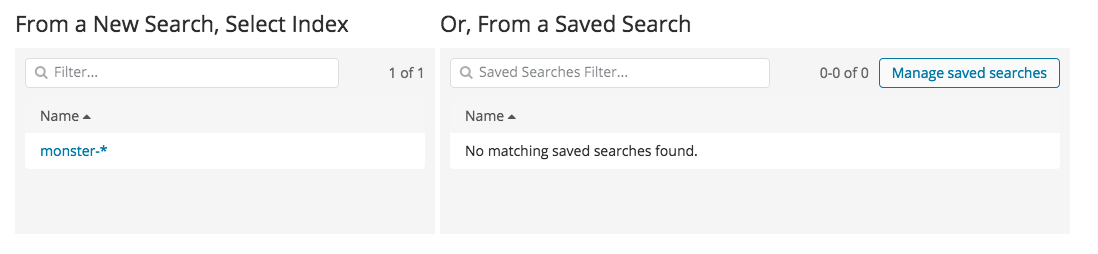
대시보드의 기본이 되는 데이터 테이블을 만드는 방법을 알아보겠습니다. Visualize 메뉴를 선택한 후 Data Table을 선택하면 아래 그림과 같은 화면을 볼 수 있습니다. 모든 Visualize 단계에서는 인덱스를 먼저 선택을 해야 합니다. 아래의 그림 같은 경우에는 monster-* 을 선택하고 다음 내용을 진행 하면 됩니다.
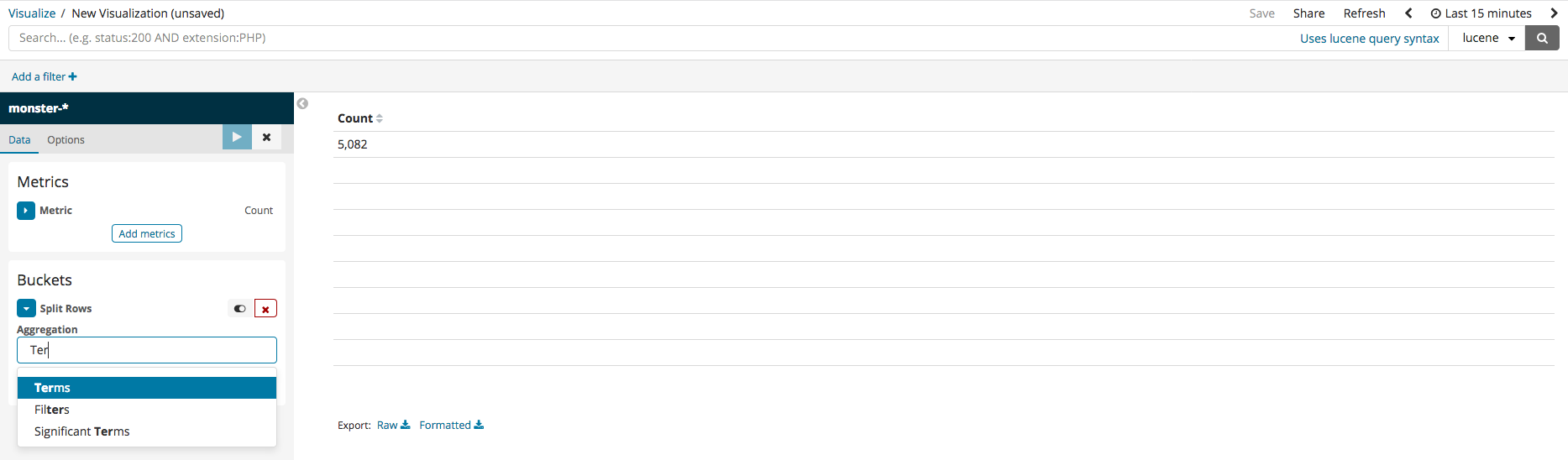
메트릭 어그리게이션은 버킷에 포함된 다큐먼트에서 계산된 통계치를 의미합니다. 버킷의 종류는 텀즈(Terms), IPv4 Range, GeoHash 등이 있습니다. 현재 사용할 텀즈 버킷이며 매트릭은 Count 입니다. 또한, 예시로 만들 데이터 테이블은 가장 많이 생성된 프로세스명과 커맨드라인을 만들어 보겠습니다. 먼저, split rows 를 선택 한 후 Terms 를 선택하면 현재 인덱스 내에 있는 모든 칼럼이 보일 것입니다. 그 중 CommandLine 을 선택한 후 실행 버튼을 누르면 카운트 수가 가장 많은 10개의 데이터를 보여주는 것을 확인할 수 있습니다.
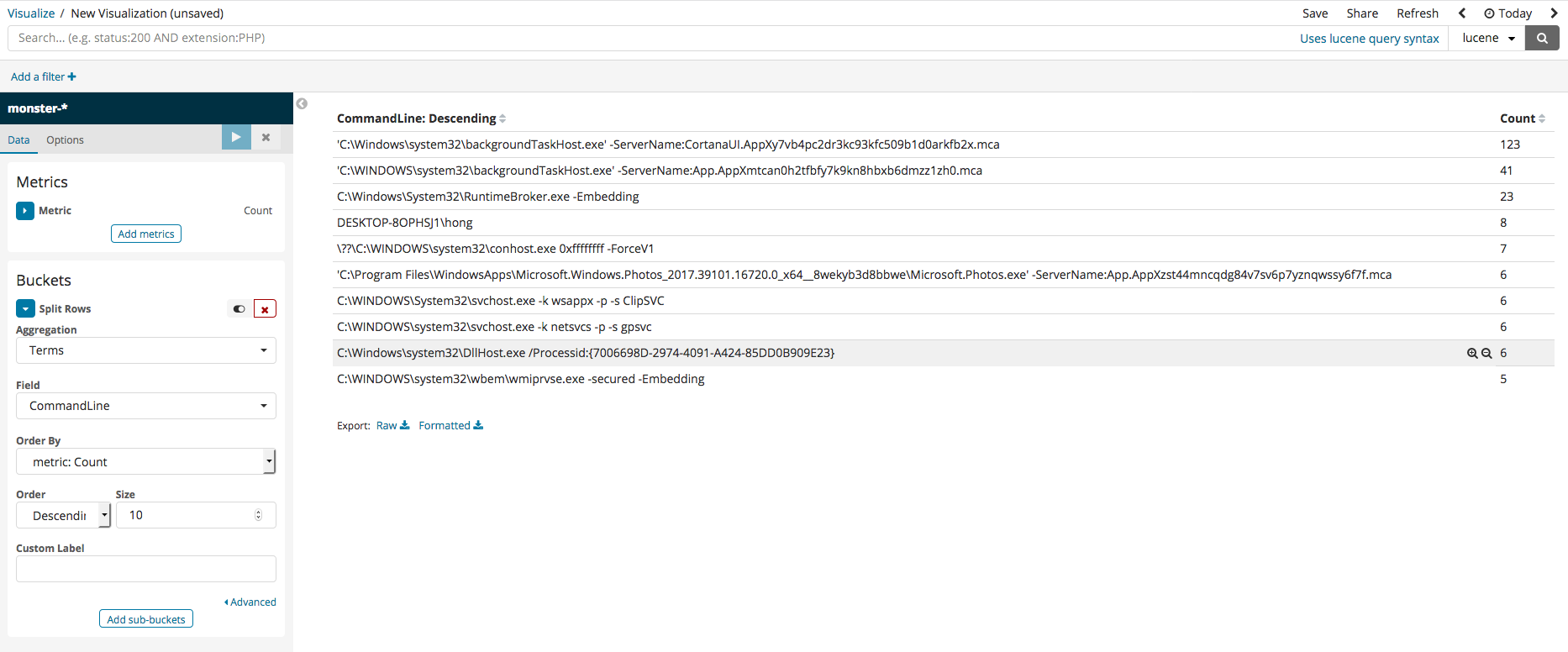
Split Rows를 한 번 더 클릭하여 칼럼을 추가할 수 있으며 CommandLine과 같은 방법으로 필드를 추가 할 수 있으며 칼럼 명은 Image를 선택하겠습니다. 모든 설정이 끝난 후 실행하면 아래 그림과 같이 나오는 것을 확인할 수 있습니다.
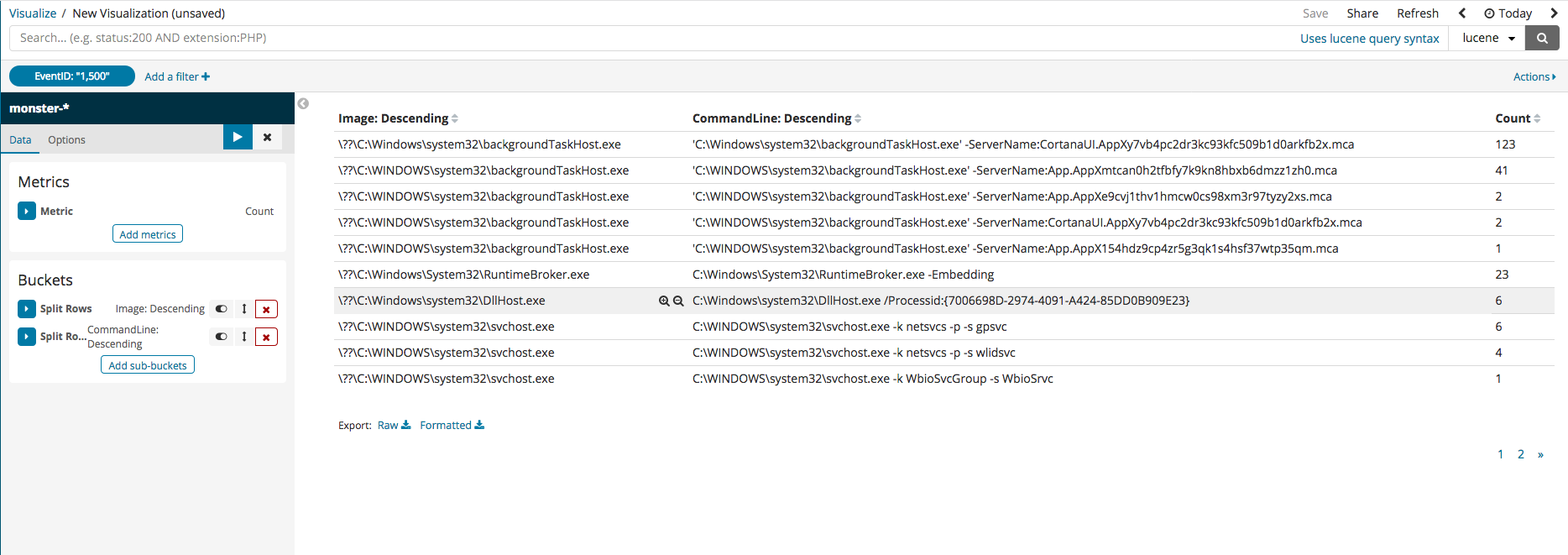
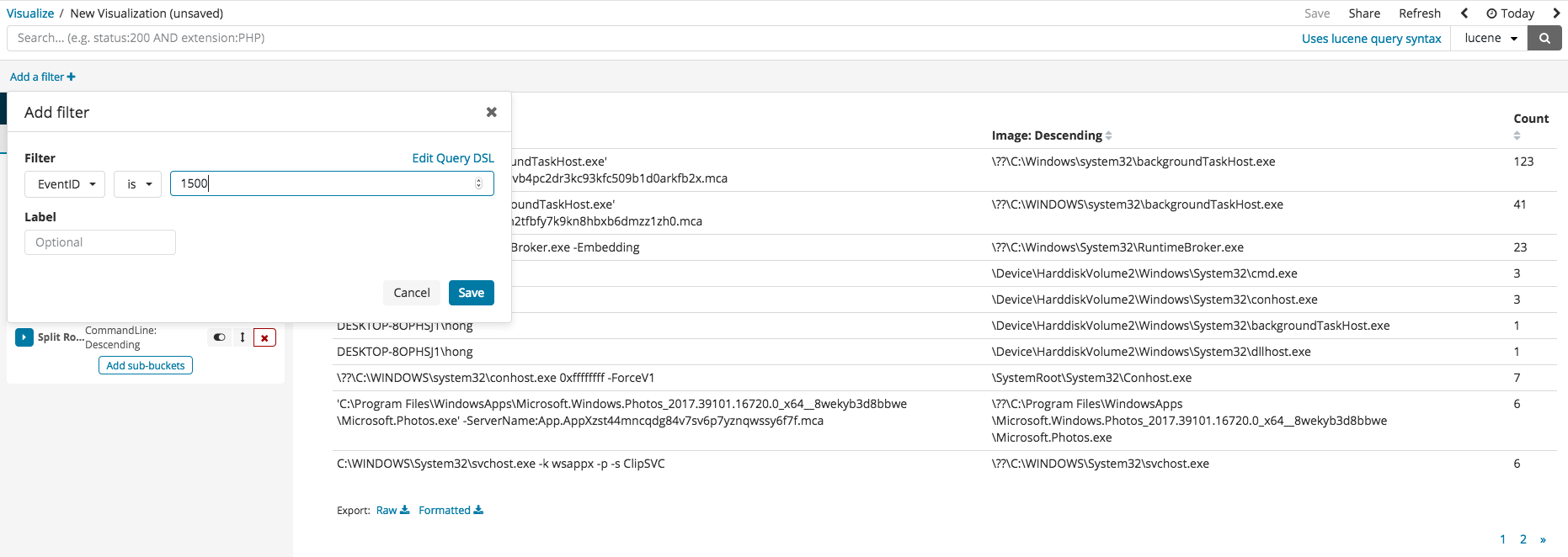
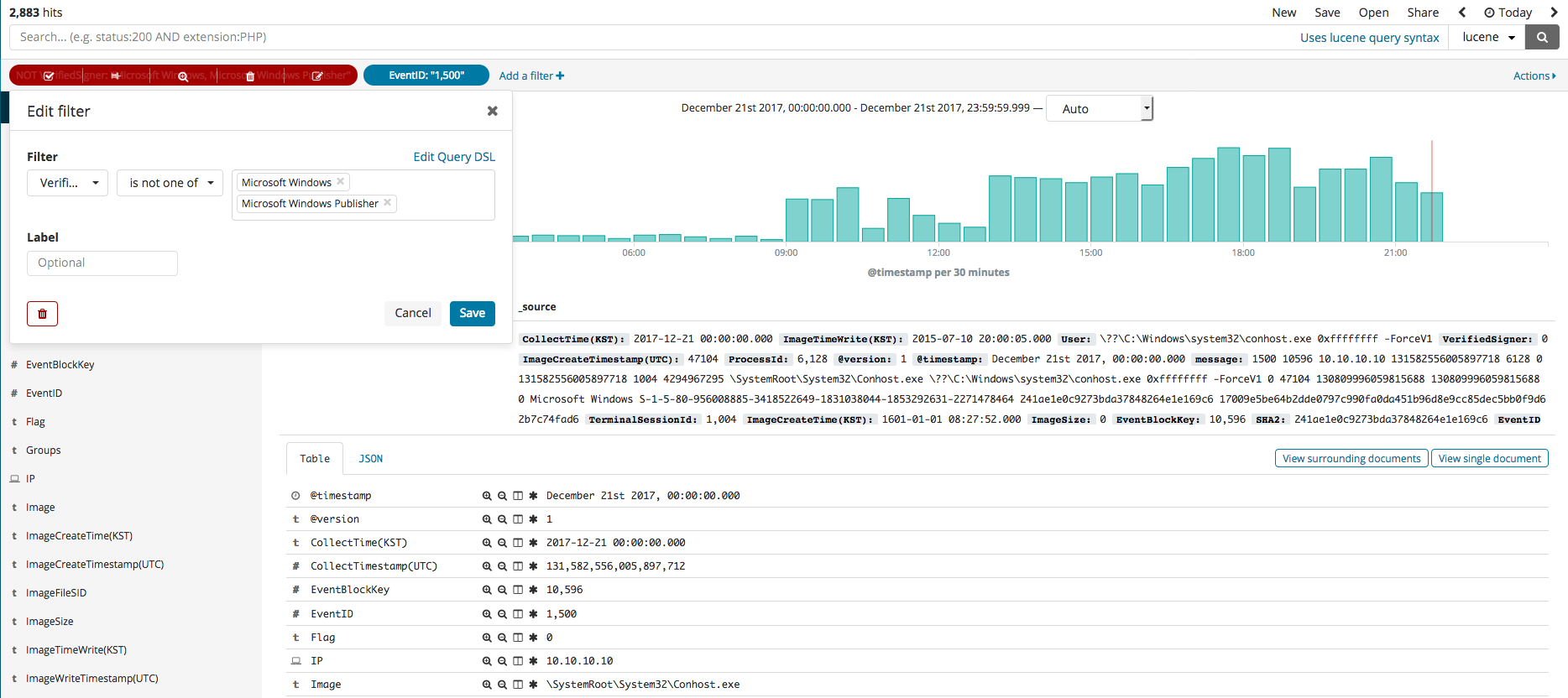
필터를 누른 후 현재 인덱스 내에 칼럼값을 가지고 필터링을 진행할 수 있습니다. 아래 그림은 EvenID 가 1500번인 것만 필터링하는 예제이며 프로그램 서명자에 대한 정보를 필터링을 설정하여 신뢰할 수 없는 서명자 혹은 서명 상태가 이상한 경우만 필터링하여 볼 수 있습니다.
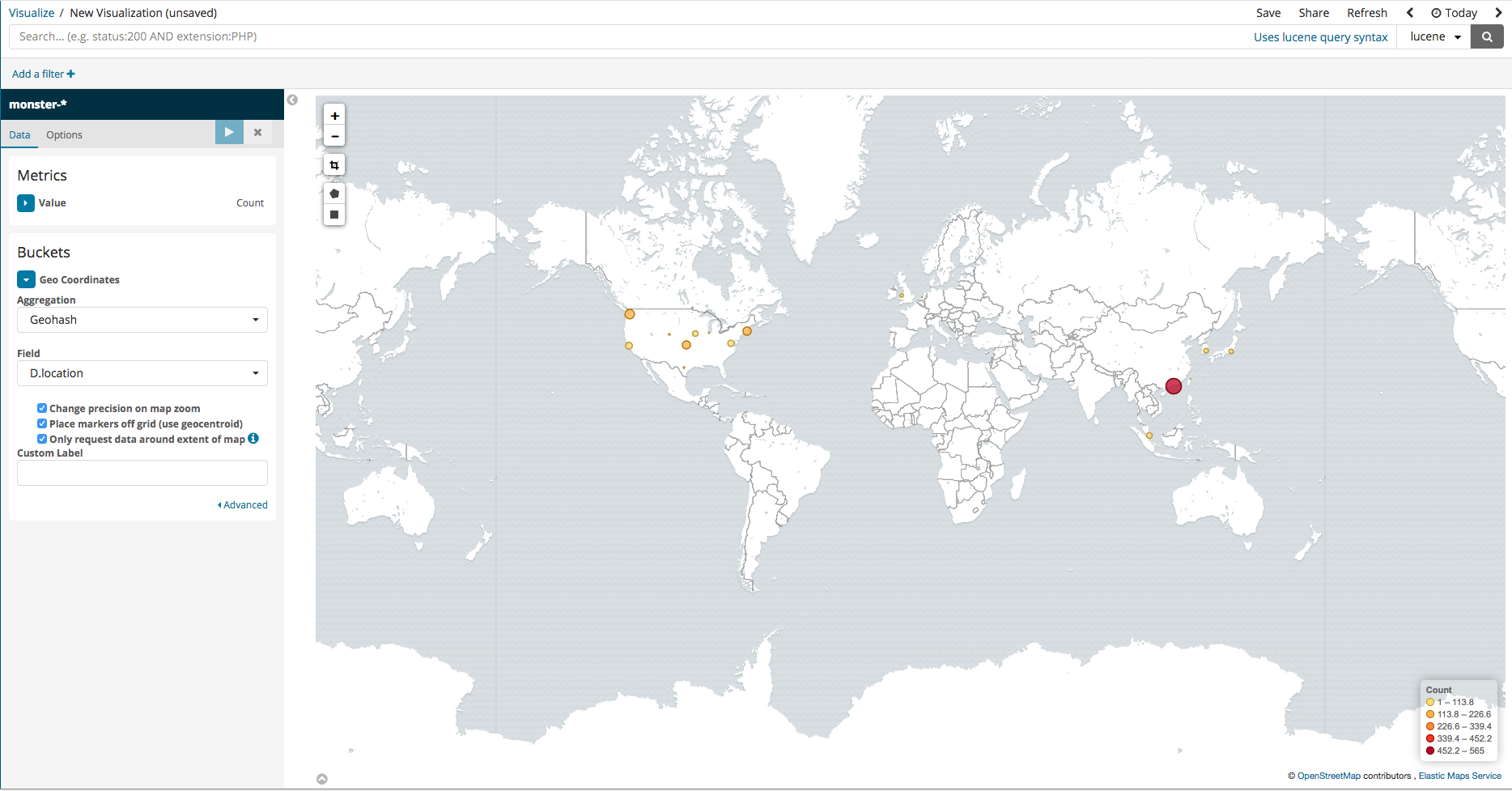
Coordinate Map
수집된 이벤트 중 DestincationIP인 경우 지리적 위치 정보를 분석 하여 엘라스틱서치에 함께 입력됩니다. Kibana 시각화 요소 중 이 정보를 이용하여 지도상에서 표시 할 수 있는 기능이 있으며 다음 순서로 설정 할 수 있습니다.
Pie
원형 그래프를 이용 하여 파일 이벤트의 타입, 레지스트리 이벤트의 타입, 목적IP, 목적 PORT와 같은 정보들을 시각화 할 수 있습니다. Split Slices 를 누른 후 데이터 테이블과 동일 하게 텀즈를 선택 후 DestinationIP 의 카운트 수가 높은 순서로 10개를 보여줍니다.


Vertical Bar
몬스터 에이전트가 다양한 호스트에 설치가 되어 있다고 가정을 한 후 호스트별 수집된 이벤트들의 통계를 표시하는 예제를 만들어 보겠습니다. Visualize 메뉴에서 Vertical Bar를 선택한 후 먼저 보이는 화면은 아래와 같으며 X-Axis를 먼저 설정해줍니다. 설정 후 실행하면 하나의 막대 그래프에서 호스트별 수집된 이벤트 아이디별로 분류되는 것을 확인할 수 있습니다.

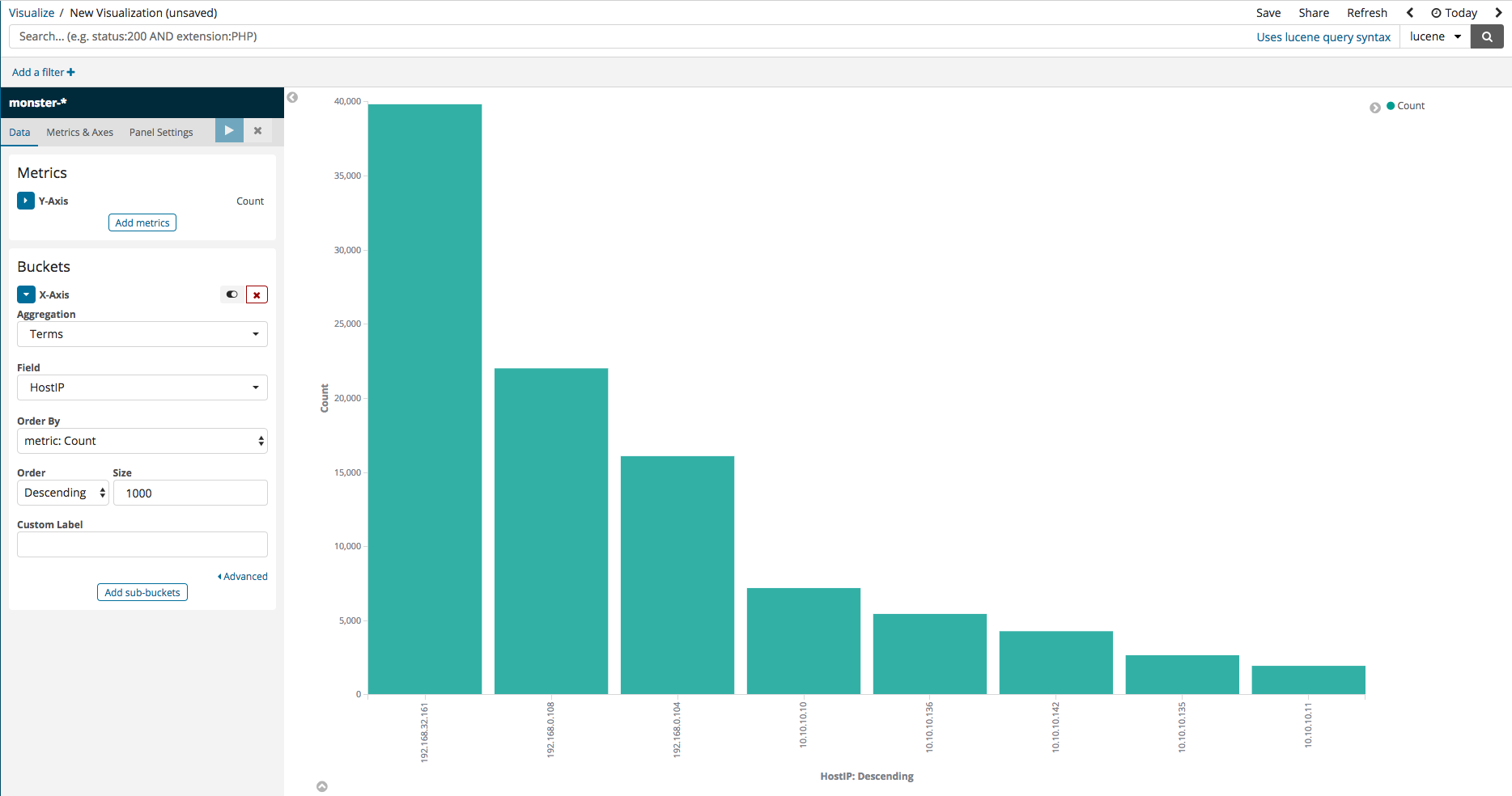
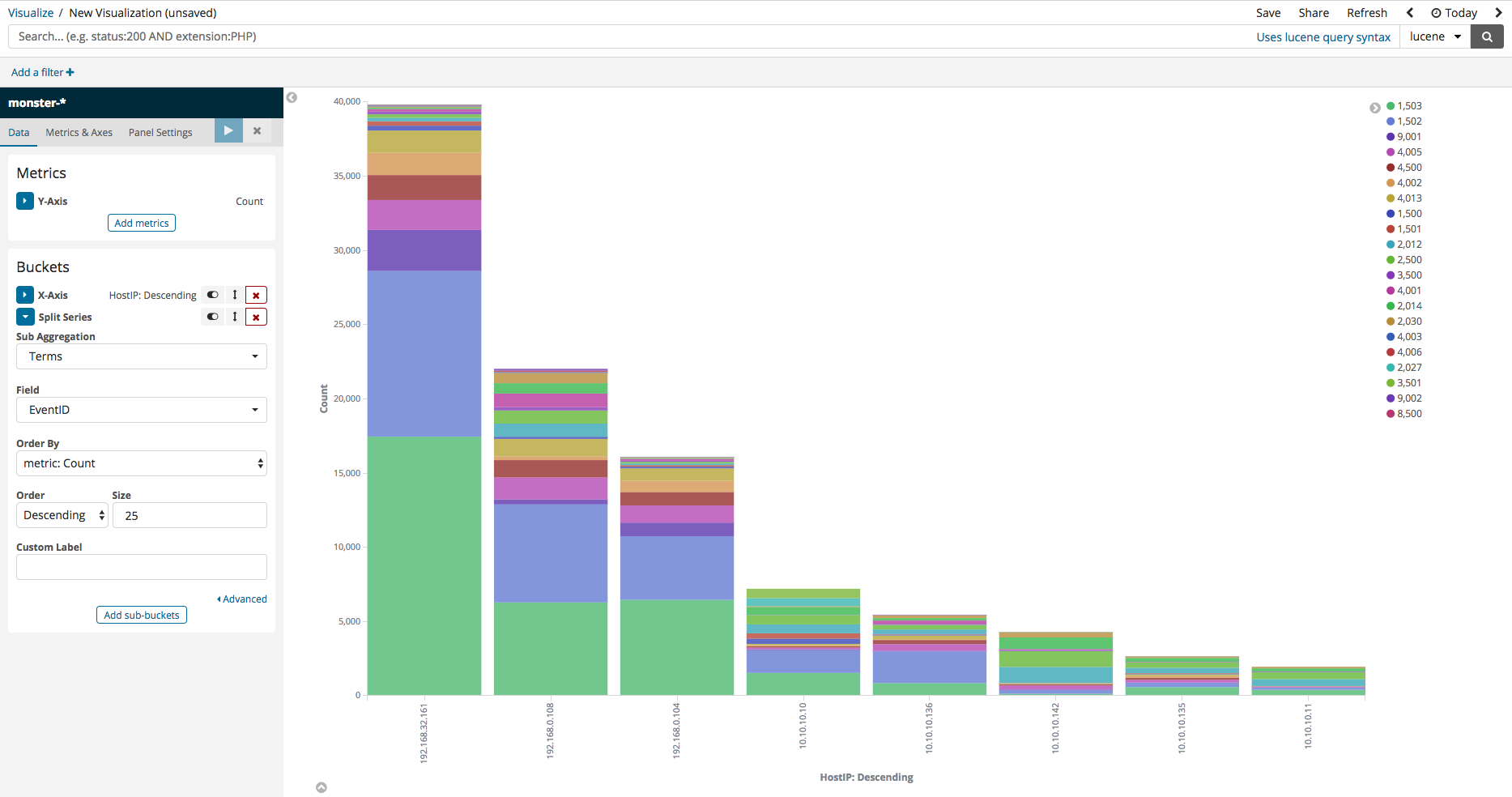
다음으로 Add-Sub-buckets 을 누른 후 Split Series 를 선택합니다. 아래 그림과 텀즈를 선택 하고 칼럼을 이벤트 아이디로 지정을 하면 아래 그림과 같이 이벤트 아이디별 통계를 확인 할 수 있습니다.
TimeLion
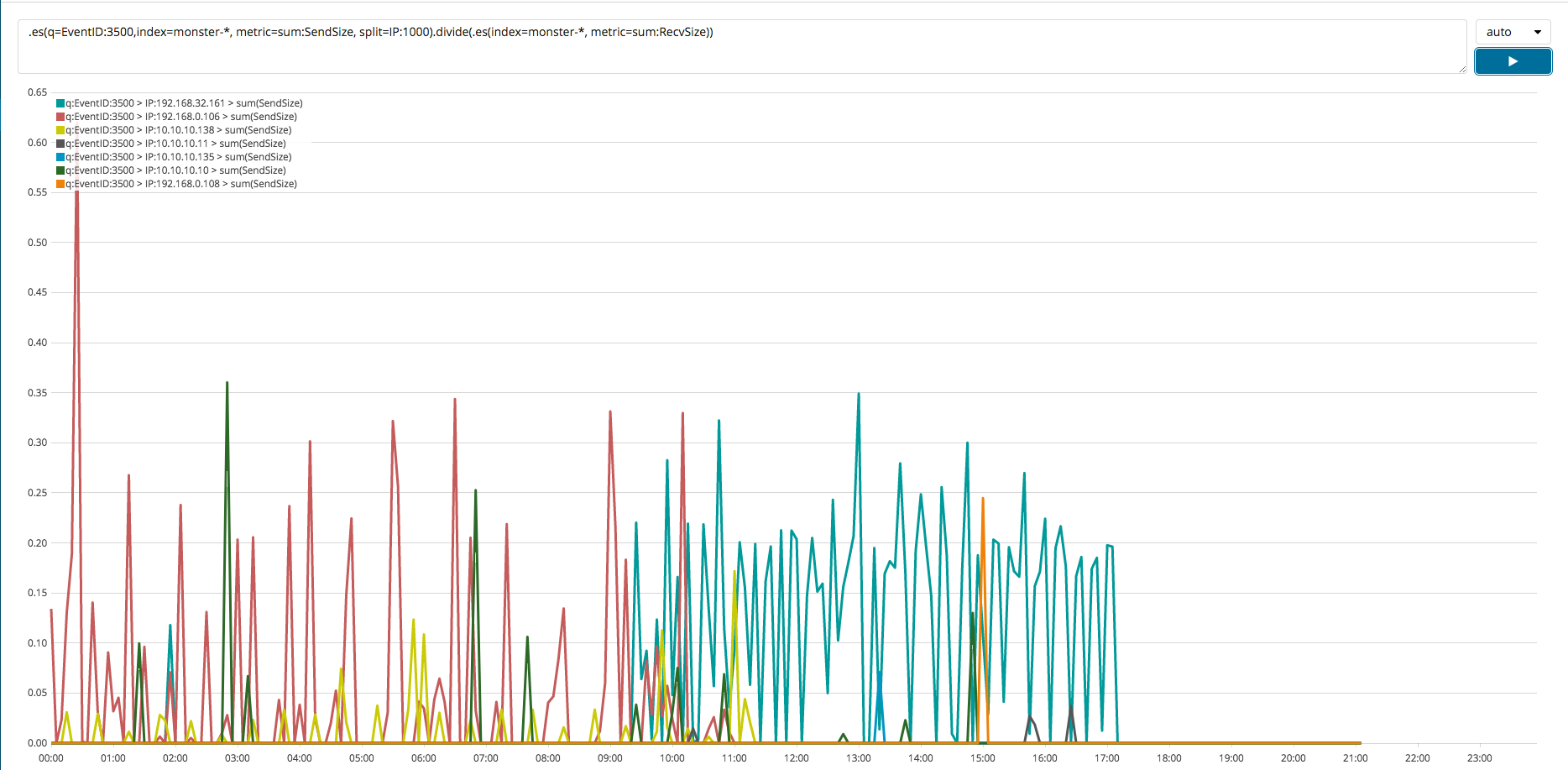
시계열 분석에 대한 예제를 간단하게 살펴보겠습니다. 호스트 시스템에서 외부로 전송한 네트워크 데이터의 총합과 수신한 데이터의 총합을 나누었을 때 1보다 큰 경우 외부로 전송한 데이터가 더 많다는 것을 추측해 볼 수 있습니다. 이러한 분석을 통해 내부 시스템에서 외부 시스템으로 데이터 유출 탐지에 활용할 수 있습니다. 이처럼 TimeLion을 활용하여 질의 문과 필터를 사용하여 다양한 시계열 분석을 시도해 볼 수 있습니다. 다음과 같은 질의 문을 실행을 해보면 아래 그림과 같은 결과를 얻을 수 있습니다.
.es(index=monster-*, metric=sum:SendBytes, split=IP:1000).divide(.es(index=monster-*, metric=sum:RecvBytes))
Dashboard
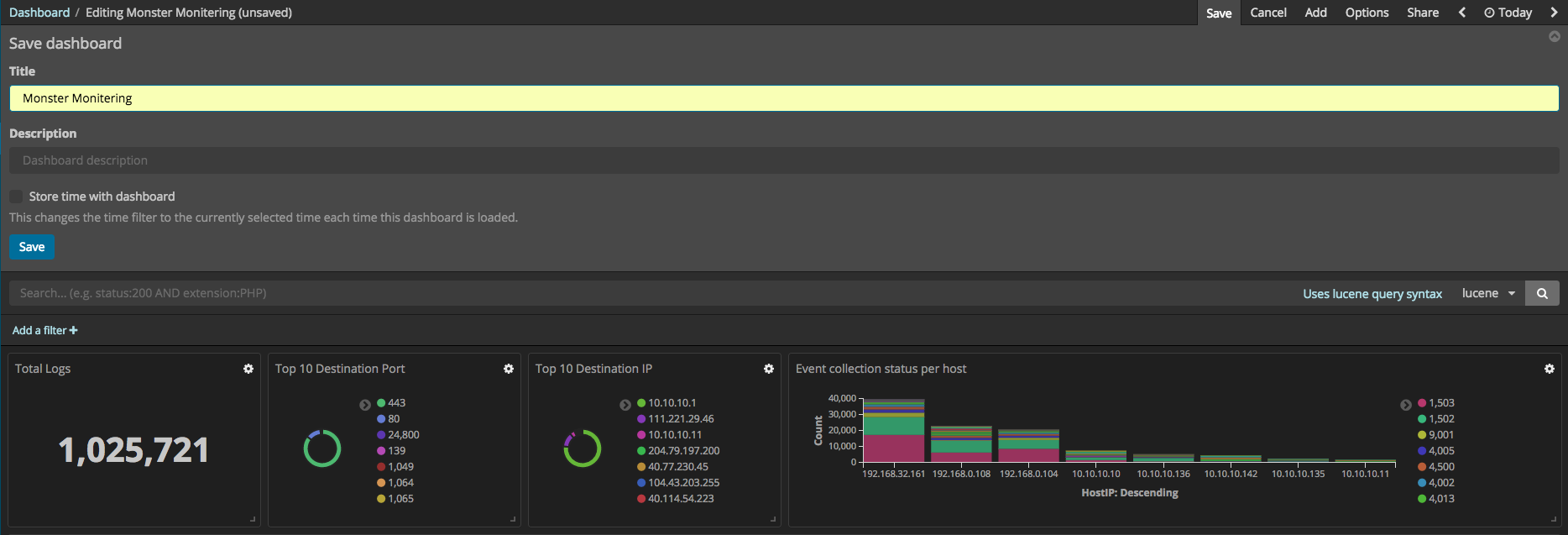
개별적인 시각화 요소들을 만드는 방법을 앞에서 살펴 보았습니다. 개별적으로 만든 시각화들을 Kibana에서는 대시보드로 구성할 수 있는 기능을 제공합니다. Kibana에서 대시보드 메뉴를 선택 후 생성되어 있는 대시보드가 없다면 Create a dashboard 라는 버튼을 볼 수 있습니다. 버튼을 누르면 대시보드를 만들 수 있는 화면이 나옵니다. 이후 대시 보드 상단에 Add 버튼을 누른 후 자신이 만든 개별적인 시각화 요소들을 클릭한 후 자유자재로 배치 할 수 있습니다. 모든 대시 보드 구성이 끝난 후 저장 버튼을 눌러 대시보드를 저장할 수 있습니다. 수집된 모든 이벤트의 개수는 42 Metric 이라는 시각화 요소를 이용하여 만들 수 있습니다.
Discover
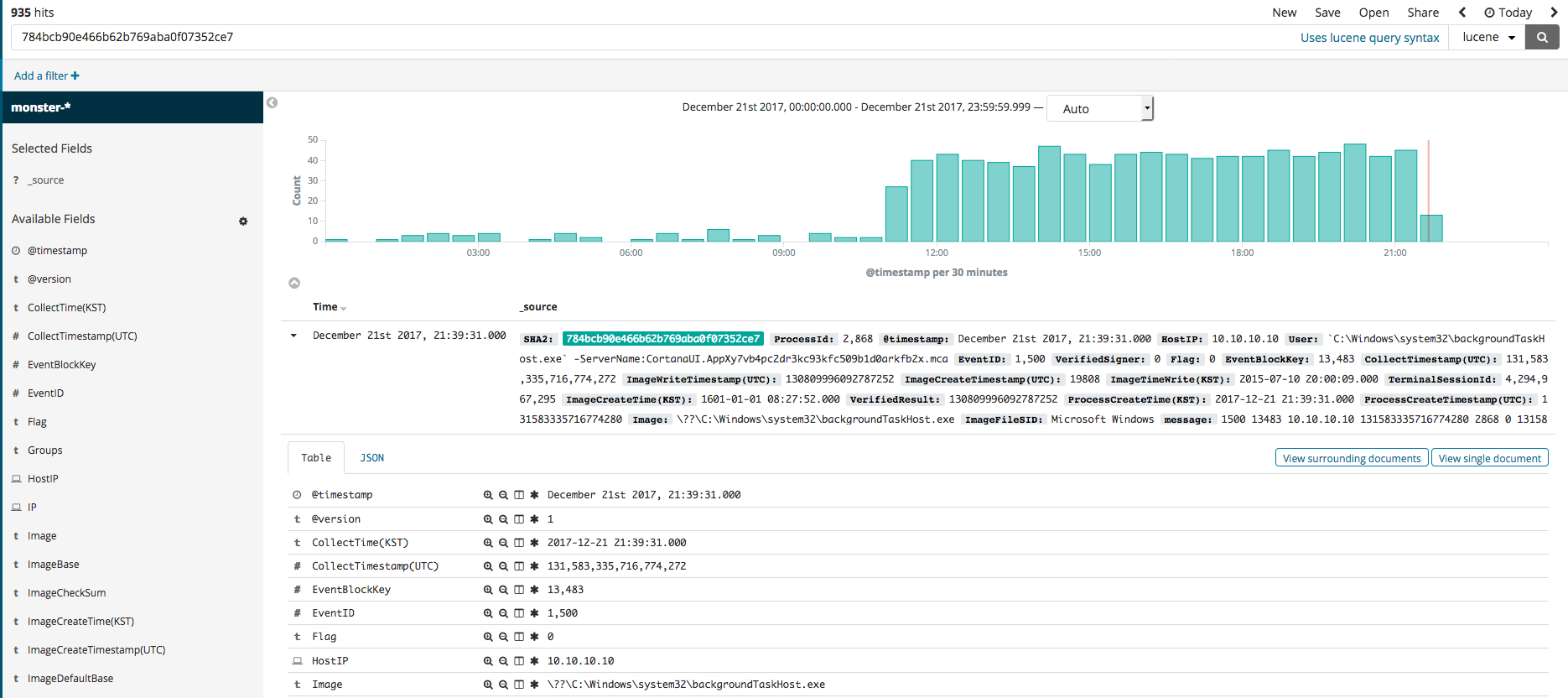
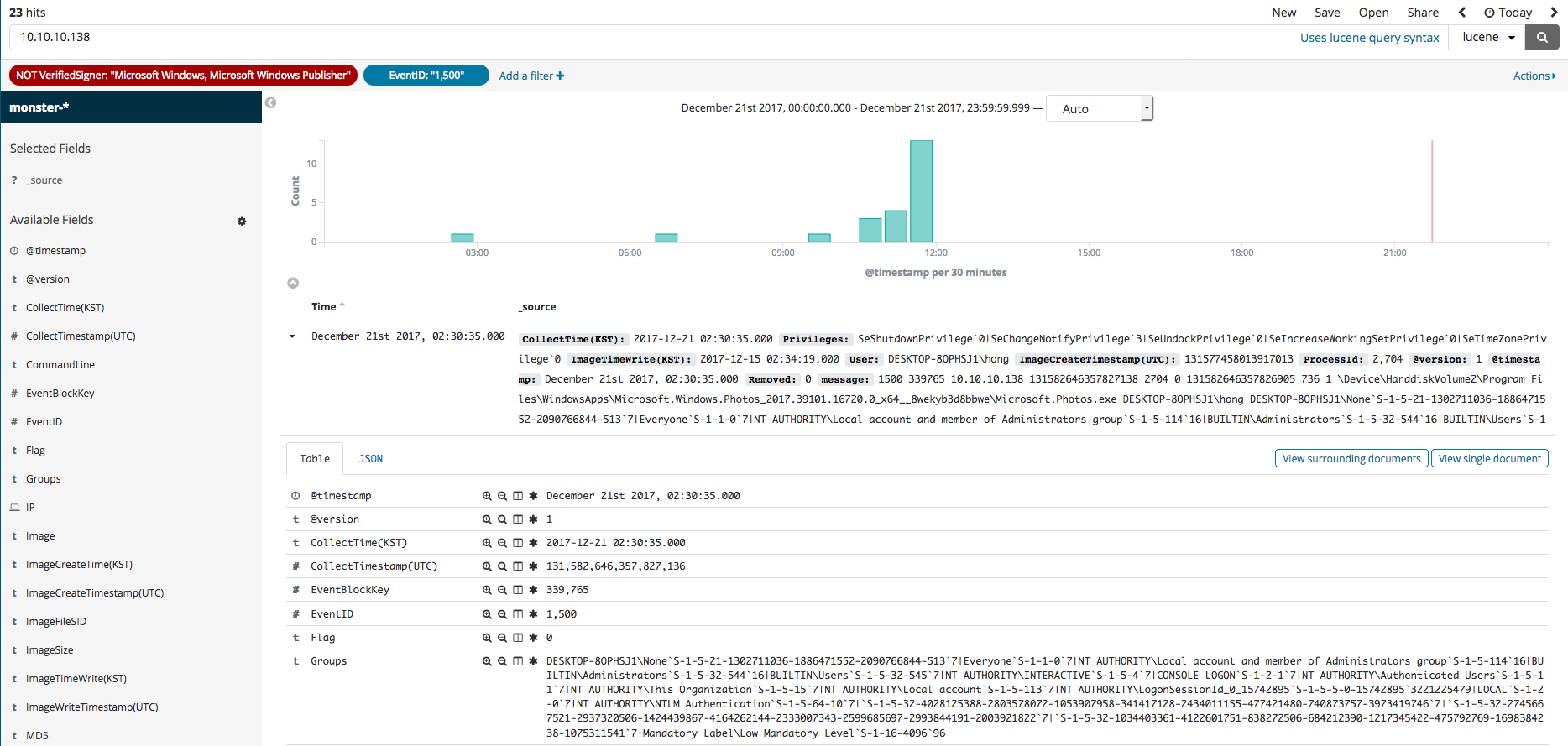
Kibana 기능 중 하나인 Discover를 이용하여 수집된 이벤트들을 검색하고 필터링하는 방법을 살펴보았습니다. Discover 메뉴를 선택하면 검색창이 보이며 해당 검색창에 검색하고자 하는 내용 검색 및 컬러 데이터 필터와 같은 작업을 할 수 있습니다. 예를 들어서 SHA2 해시값을 검색하면 아래 그림과 같이 나오는 것을 확인할 수 있습니다. 두 번째 그림은 수집된 모든 이벤트에서 마이크로소프트 서명자가 아니고 프로세스 생성 이벤트를 필터링한 결과입니다. 세 번째 그림은 프로세스 생성 이벤트이고 서명자가 마이크로소프트가 아닌 이벤트에서 특정 아이피를 검색한 결과입니다.
참고자료
- 엘라스틱서치 소개 및 관계형 데이터베이스와 용어 비교
- https://www.slideshare.net/clintongormley/cool-bonsai-cool-an-introduction-to-ElasticSearch
- Building a Sysmon Dashboard with an ELK Stack
- https://cyberwardog.blogspot.kr/2017/03/building-sysmon-dashboard-with-elk-stack.html
- Monitoring for Windows Event Logs and the Untold Story of proper ELK Integration
- http://www.ubersec.com/2017/12/03/monitoring-for-windows-event-logs-and-the-untold-story-of-proper-elk-integration/